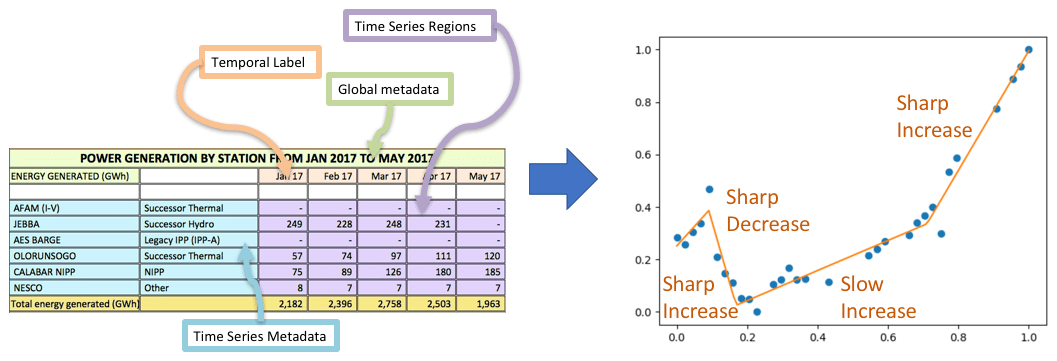
A wealth of knowledge is contained in time series data, ranging from commodity prices to censuses of populations displaced by famine. Unfortunately, this knowledge is often stored in spreadsheets that lack a standard format or labeling conventions. As part of the DARPA Causal Exploration project, we are building systems to unlock the data in these spreadsheets and make it easily accessible and interpretable to people. Our systems learn the layout and representation of spreadsheet data automatically, extract useful data into a knowledge graph, and provide a human-interpretable summary of the high-level trends in the data. Our time series extraction toolkit has been applied to datasets ranging from World Bank development indicators to food prices in Africa, generating a corpus of over ten thousand processed time series and accompanying interpretable trends.