Entity Extractors In One Hour - Created with Haiku Deck, presentation software that inspires
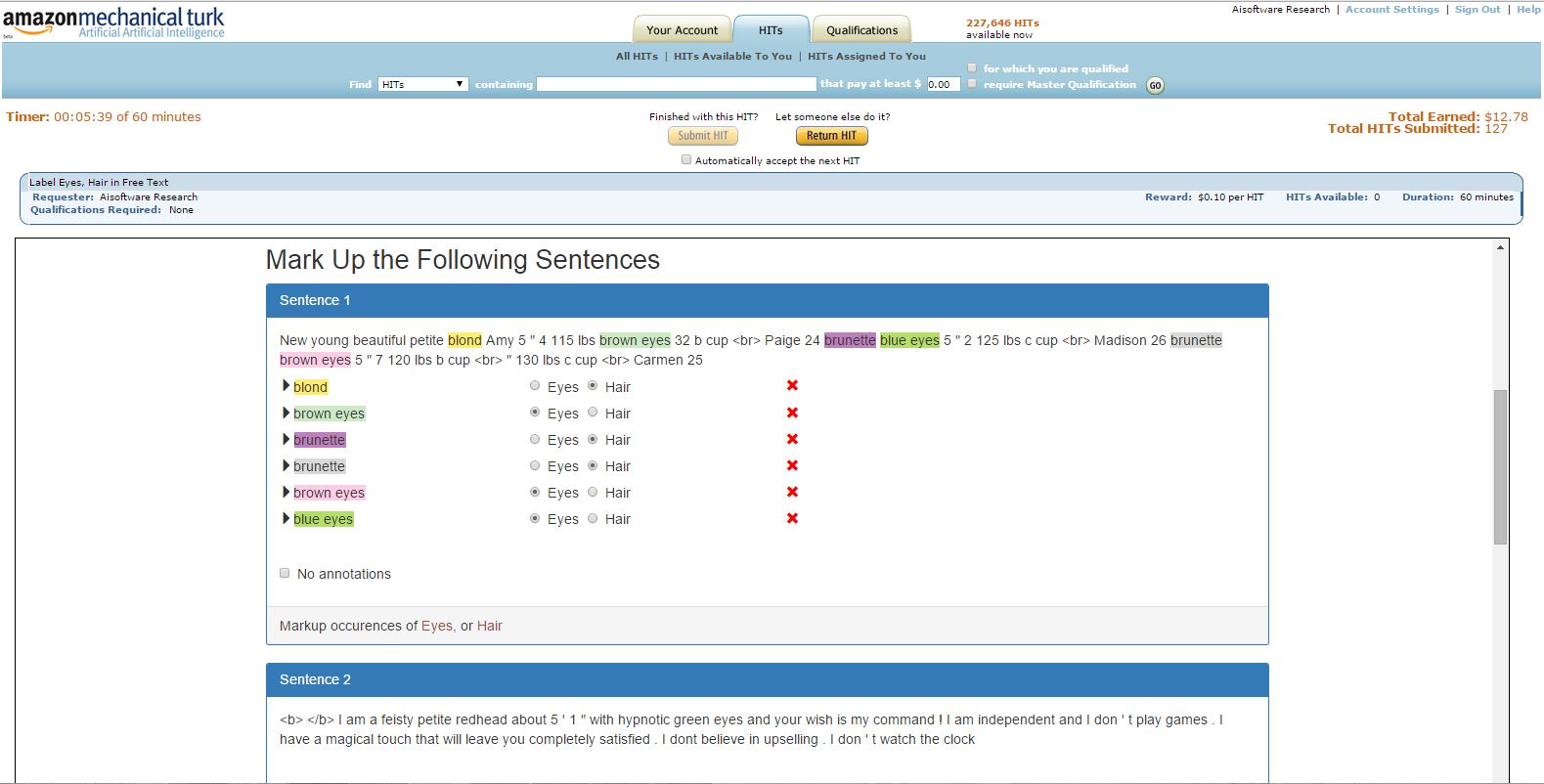
MTurk hits can be run in sandbox (developer) or live environment. Hits can be created with/without qualifications. All the possibilities are explained below.
We will be definining an extraction which is named; the name forms the identifier for this effort. This identifier must be chose as a string which can be safely used as a directory component with only lower case letters, digits and the underscore character. For example, we might define a catalog extraction for getting information from online stores, or a makemodel for extracting atributes of automobiles for sale.
Within our extraction we will be defining one or more categories. A category is a class of entities to be recognized and extracted. For example, in the catalog extractor, we might define categories price, description, and modelnumber. The category names should be simple identifiers with only lower case letters, digits, and the underscore character. Each category also has an English label, suitable for presentation to users, which can include spaces and upper case letters. For example, in the catalog extractor, we might define the category labels as "Price", "Item Description", and "Model Number".
We will define a corpus of example texts too train and test our extractors. These are conventionally called sentences but they may be fragments of a sentence, multiple sentences, etc., as long as they can be annotated by users in the interface without scrolling. These sentences should have a fair number of instances of the categories of this extraction.
Mechanical Turk microwork tasks are conventionally termed hits and we will use that terminology as well.
Some Mechanical Turk extractions will benefit from having the workers undergo training and vetting. This project includes capabilities to define and populate an optional special task, called a qualification task, to carry this out.
pip install requestspip install botopip install nltkpip install awscli$HOME.~/.bashrc, ~/.profile, or ~/.bash_profile
export GITHUB=<your github repository root folder>
export PATH="$PATH:$GITHUB/dig-mturk/generic/scripts"
source <shell init file>cd $GITHUB/dig-mturk; git checkout master; git pull; cd mturk; mvn clean installcd $GITHUB/Web-Karma; git checkout development; git pull; mvn clean installaws configurecd $GITHUB/dig-mturkexport EXTRACTION=<extraction>newExtraction.sh $EXTRACTION This will create $GITHUB/dig-mturk/extractions/$EXTRACTION and copy/adapt a few files from $GITHUB/dig-mturk/extractions/boilerplate/ to $GITHUB/dig-mturk/extractions/$EXTRACTION/$GITHUB/dig-mturk/extractions/$EXTRACTION/sentences.txt to contain the sentence data, one sentence per line.$GITHUB/dig-mturk/extractions/$EXTRACTION/fetchSentences.sh and/or $GITHUB/dig-mturk/extractions/$EXTRACTION/query.json to specify the index name, desired hit count, credentials, query fields, and query path. Then execute the script:fetchSentences.sh $EXTRACTION $TRIAL $SIZE where $SIZE is the number of sentences to be fetched from ES. This will generate $GITHUB/dig-mturk/extractions/$EXTRACTION/sentences.json.$GITHUB/dig-mturk/extractions/$EXTRACTION/create.cfg is a configuration file with parameters defining how Mechanical Turk tasks are created.[create] section, edit parameters to specify the desired number of hits to be created, the number of sentences in each hit, etc. If your data comes from ElasticSearch, be sure the [field] parameter specifies how data is obtained from each ElasticSearch result 'hit'. In the [boto] section, edit the parameters to specify the AWS/S3 configurations specified above.$GITHUB/dig-mturk/extractions/$EXTRACTION/hitdata.pyfmt is a template file specifying details of Mechanical Turk hits. For this file, you should edit the task description, title, and categories. You should leave the scratch_category as it is. You may wish to edit the keywords. You should leave the bracketed expressions {instructions}, {qualifications} and {sentences} as they are: they will be filled in by the page generator.$GITHUB/dig-mturk/extractions/$EXTRACTION/head.html, $GITHUB/dig-mturk/extractions/$EXTRACTION/instructions.html, and $GITHUB/dig-mturk/extractions/$EXTRACTION/tail.html will be combined to become an instructions page for the users.
$GITHUB/dig-mturk/extractions/$EXTRACTION/head.html: no change.$GITHUB/dig-mturk/extractions/$EXTRACTION/instructions.html: Change the sample content and the categories to conform to your categories and likely data. There are five necessary modifications in $GITHUB/dig-mturk/extractions/$EXTRACTION/instructions.html. Each is introduced by a comment suggesting what needs to be changed.$GITHUB/dig-mturk/extractions/$EXTRACTION/tail.html: Change the $GITHUB/dig-mturk/extractions/$EXTRACTION/tail.html if you consider the standard boilerplate text confusing in context when presented to a user as part of the instructions.cd $GITHUB/dig-mturk/extractions/$EXTRACTION; cat head.html instructions.html tail.html > page.html; open page.html$GITHUB/dig-mturk/extractions/$EXTRACTION/karma/ folder contains information so that the Karma information integration system can transform the Mechanical Turk workers' outputs into a format useful for training a CRF model.
$GITHUB/dig-mturk/extractions/$EXTRACTION/karma/preloaded-ontologies/mturk-ontology.ttl: Define the categories as relations (see embedded example) and use the labels as the rdfs:label.$GITHUB/dig-mturk/extractions/$EXTRACTION/karma/python/mturk.py: In the definition of data structure categoryToAnnotationClass at the top of the file, insert a mapping between your categories and their labels.$GITHUB/dig-mturk/extractions/$EXTRACTION/qualification/ folder contains specifications and files used to specify a qualification task. (See below.)The qualification task is a small test where the user practices annotating examples before performing the real, paid tasks. The objective of the test is to teach the user by practicing, so for each wrong answer the user receives feedback with the explanation of how to correctly answer it. Once the user has successfully completed the qualification task, he/she will be allowed to continue to the actual tasks. A user who is not successful at the qualification task can try again after a specified delay.
If an extraction requires qualification, the qualification task has to be generated before creating hits. A user wishing to perform a hit belong to your extraction will be first directed to satisfy the qualification if you have specified one.
To generate a qualification task, you need the following:
$EXTRACTION as the name of the qualification.newQualification.sh $EXTRACTION- this will copy config JSON from $GITHUB/dig-mturk/extractions/boilerplate/qualification/ to $GITHUB/dig-mturk/extractions/$EXTRACTION/qualification/qual_${EXTRACTION}.json. It will also generate qualification.cfg.$GITHUB/dig-mturk/extractions/$EXTRACTION/qualification.cfg to reflect your organization name, Amazon S3 bucket name, Amazon access_key_id and Amazon secret_access_key.$GITHUB/dig-mturk/extractions/$EXTRACTION/qual_${EXTRACTION}.json to reflect categories, sentences, answers, etc. to define your qualification domain. Note: the JSON key explanation.wrong needn't be edited. The script will populate this field as required before generating HTML.For each sentence, change:
\t. If there is no answer for this category, set as "".newQualification.sh $EXTRACTION- this will copy config JSON from $GITHUB/dig-mturk/extractions/boilerplate/qualification/ to $GITHUB/dig-mturk/extractions/$EXTRACTION/qualification/qual_${EXTRACTION}.jsongenerateQualification.sh $EXTRACTION --publish --upload. This will generate and publish the qualification page HTML and assets to Amazon S3, based on the qual_${EXTRACTION}.json data.generateQualification.sh $EXTRACTION --render (optional) can be used to preview the qualification test sentences and correction essages (message presented to user after incorrect response).deployQualification.sh -sandbox $GITHUB/dig-mturk/extractions/$EXTRACTION/qualification.cfg to create qualification in sandbox. This will update qualification.cfg with the qualification ID generated by Amazon for sandbox trials of the qualification test.deployQualification.sh -live $GITHUB/dig-mturk/extractions/$EXTRACTION/qualification.cfg to create qualification in live. This will update qualification.cfg with the qualification ID generated by Amazon for live use by any interested Turkers.$GITHUB/dig-mturk/mturk/src/main/python/respondQualification.py every 5 minutes. This job approves/rejects all qualification requests.You may want to edit $GITHUB/dig-mturk/extractions/$EXTRACTION/create.cfg for a small number of hits, small number of sentences/hit.
export TRIAL=<trial>mkdir $GITHUB/dig-mturk/extractions/$EXTRACTION/$TRIALcreateHits.sh sandbox $EXTRACTION $TRIAL. This will create config json for hits and upload it to S3 at extractions/$EXTRACTION/$TRIAL/config/.deployHits.sh -sandbox $EXTRACTION $TRIAL. This will create all files requires to create a HIT and publish those to $BUCKET/extractions/$EXTRACTION/$TRIAL/hits/ in S3 and will also yield a few sandbox URLs, which you can annotate yourself to test things out. If hit was created requiring qualification you need to take the qualification test to be qualified before you are allowed to do the hits, even for sandbox deployment.hitResults.sh -sandbox $EXTRACTION $TRIAL. This will approve the unapproved assignments of the hits and create tab separated result files in S3 in $BUCKET/extractions/$EXTRACTION/$TRIAL/hits/.When your task well formed, you are ready to create live hits for the Mechanical Turk community to perform for you.
You may want to edit $GITHUB/dig-mturk/extractions/$EXTRACTION/create.cfg to significantly increase the number of hits and/or to standardize the number of sentences/hit.
export TRIAL=<trial>mkdir $GITHUB/dig-mturk/extractions/$EXTRACTION/$TRIALcreateHits.sh $EXTRACTION $TRIAL. This will create config json for hits and upload it to S3 at extractions/$EXTRACTION/$TRIAL/config/.deployHits.sh -live $EXTRACTION $TRIAL. This will create all files requires to create a HIT and publish those to extractions/$EXTRACTION/$TRIAL/hits/ in S3 and yield a few sandbox URLs, which you can annotate yourself to test things out. If hit was created using qualification you need to take the qualification test, get qualified before you are allowed to do the hits.hitResults.sh -live $EXTRACTION $TRIAL. This will create all files requires to create a HIT and publish those to $BUCKET/extractions/$EXTRACTION/$TRIAL/hits/ in S3.Since these are processing done on results fetched from hits and stored in S3, these steps don't depend on the staging area (live/sandbox) of the hits.
consolidateResults.sh $EXTRACTION $TRIAL# Note: no -sandbox since it is independent of Mturk. This will consolidate the result files for all hits in a particular trial.fetchConsolidated.sh $EXTRACTION $TRIAL. This will download consolidated result file from S3.modelConsolidated.sh $EXTRACTION $TRIAL. This will do offline karma model for the results fetched from S3.adjudicate.sh $EXTRACTION $TRIAL. This will compute the agreement amongst the Turkers for each annotation. Adjudicated results are in $GITHUB/dig-mturk/extractions/$EXTRACTION/$TRIAL/adjudicated_$EXTRACTION_$TRIAL.jsonThis research is supported by the Defense Advanced Research Projects Agency (DARPA) and the Air Force Research Laboratory (AFRL) under contract number FA8750-14-C-0240.
1 The student Lidia Ferreira thank to Science Without Borders Program, CAPES Scholarship - Proc. Nº 88888.030514/2013-00.