| Entity Linkage | |||
| The current approaches for linking information across sources, often called record linkage, require finding com-mon attributes between the sources and comparing the records using those attributes. This often leads to unsatisfactory results because the sources are often missing information or contain incorrect or outdated information. We are addressing this problem by developing the technology to build massive entity knowledgebases, which we call EntityBases. The key idea is to create a comprehensive knowledgebase for the entities of interest (e.g., companies). In order to build such a knowledge base, we must address the issues of linking entities with multi-valued attributes obtained from heterogeneous sources and providing a virtual repository that can be efficiently queried. | |||
| Motivating Example | |||
| Consider the following real-world example of the need for EntityBases. Figure 1 shows extracts of two news releases from the U.S. Immigration and Customs Enforcement, an agency of the U.S Department of Homeland Security. The documents describe a case involving several individuals and companies accused of illegal exports to Iran. | |||
| Entity extraction software can automatically extract entities, such as company, person or location names, from these documents. For example, "Mohammad Ali Sherbaf", "Kenneth L. Wainstein", and "Khalid Mahmood Chaudhary", etc., would be recognized as person names. Similarly, "Sepahan Lifter Company", "Sharp Line Trading", and "Clark Material Handling Corporation" would be labeled as companies, and "Esfahan" as a city and "Iran" as a country. | |||
| However, simple entity extraction is not enough. The relationship between these two documents cannot be established without the kind of record linkage reasoning that our EntityBase provides. In particular, note that the 2002 document refers to one of the key persons involved in the case as "Mohammad Ali Sherbaf" while the 2006 document as "Mohammad A. Sharbaf" (even though the documents come from the same government agency). Different transliterations of foreign names, such as in this case, would foil simple match techniques. The multiplicity of names that refer to the same real-world entity is not limited to people --- other entities, such as companies and locations, exhibit the same phenomenon. For exam-ple, both "Isfahan" and "Esfahan" are common transliterations for the same Iranian city. | |||
| The EntityBase approach uses previously gathered knowledge to help differentiate the entities that appear in docu-ments like these and provide additional information. Our EntityBase can recognize that "Mohammad Ali Sherbaf" and "Mohammad A. Sharbaf" are the same person and that "Sepahan Lifter Company", "Sepahan Lifter", "Sepahan Lifter Co." refer to the same company. Moreover, the EntityBase also shows that this company has its headquarters in "Nos. 27 and 29, Malekian Alley, North Iranshahr Ave., Tehran (15847)" and its factory in "Mahyaran Industrial Town, Isfahan"; that its commercial manager is "Mohammad Kharazi" and its headquarters’ phone and fax numbers are (+98-21) 8830360-1 and (+98-21) 8839643, respectively. At the same time, the EntityBase shows that "Sepahan Lifter Company", "Behsazan Gran-ite Sepahan Co.", or "Rahgostar Nakhostin Sepahan Co." are different companies that are all located in Isfahan, Iran. | |||
 Figure 1. Entity Resolution Problem in New Articles |
|||
| Entity Linkage | |||
| Figure 2 shows an example of the matching process. An incoming news document mentions the company "Sepahan Lifter Corp" as well as "Mohammad Sherbaf". This information can be used to query the EntityBase (which consists of millions of company entities). The blocking process efficiently identifies candidates that appear consistent with the information we know. As the example shows, many of the candidates have tokens that also appear in the query, so even applying a Jaccard-style metric (i.e., token overlap) or TF-IDF would be sufficient to yield the candidates shown. | |||
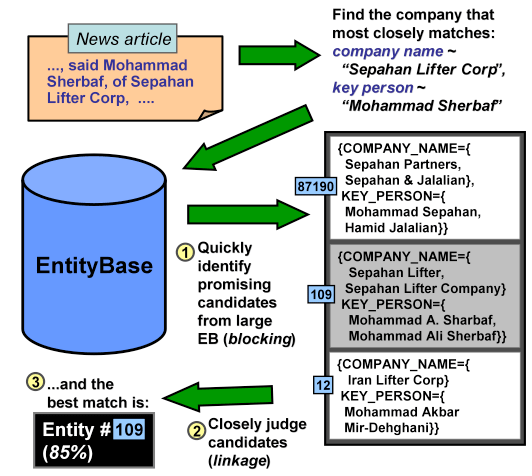 Figure 2. Entity blocking and linkage |
|||
| The linkage process then compares the data in greater detail, parsing the incoming query to realize that "Corp" is a previously unseen term associated with the company’s name, and that "Ali" is missing from Mohammad Sherbaf’s name. It also evaluates the other candidates and identifies similar differences. In evaluating the candidates, the linkage phase associates metric scores to quantify the similarity (or lack there of). A second part of the linkage process evaluates the similarities/dissimilarities and then judges the implications of such scores. For example, the linkage process could have identified that Corp is just a common company formation acronym (like "Inc." or "LLP") and that the missing "Ali" from the person’s name is not critical (as opposed to a mismatch on last name, for example). | |||
| Exploiting Geospatial Context | |||
| When querying and matching entities, we can exploit the geospatial extents of the entities to help identify and assess possible matches. Consider our running example shown in Figure 2, where a document understanding system queries the EntityBase to match the company "Sepahan Lifter Corp" and the person "Mohammad Sherbaf," which are extracted from a document. The EntityBase may provide many candidates (e.g., entity #12, #109 and #87190) even after applying the blocking process. However, by exploiting the geospatial extents of these entities, the system can deduce additional infor-mation to narrow down the relevant entities. For example, the company mentioned in the document is located within area X shown in Figure 3. The system infers that entity #109 is located within area X as well (based on its "phone" attribute). It also infers that the companies of the entities #12 and #87190 are located within area Y (based on their associated "phone" attribute). This in turn implies lower similarity between the company mentioned in the document and the two entities #12 and #87190. | |||
| One can build an EntityBase for just about any type of entity, including people, organizations, companies, terrorist groups, and so on. These knowledge bases of entities can then be used for a wide variety of applications. In this page we described how an EntityBase can be used for associating and linking text documents with the actual entities that are mentioned in the documents. An EntityBase could also be used to process data in a database or to reason about the relationships between entities (such as finding all organizations that are located in the same region and are mentioned in the same document). | |||
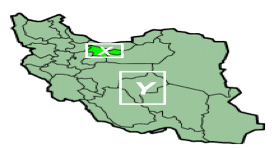 Figure 3. Geocoordinates of the companies in Iran |
|||
| This research was sponsored by the Air Force Research Laboratory, Air Force Materiel Command, USAF, under Con-tract number FA8750-05-C-0116. | |||