| Mashup Construction: Karma | |||
| Mashups provide an integrated and effective approach to extract, integrate and view diverse information. Some interesting examples of Mashups on Internet are Zillow and WikiMapia. However, the process of creating a Mashup often requires programming knowledge and background information of widgets to use existing technologies such as Yahoo Pipes and Intel Mashmaker. Therefore, we have developed a system called Karma where the user is able to create a Mashup in a one seamless interactive process using the programming by demonstration paradigm. It allows end-users to rapidly acquire the relevant data, get it into an appropriate format, combine it with other sources of information, visualize the data in various ways, and export the data in a structured format so that it can be used with other tools. | |||
| In Karma, a user doesn't’t have to program or understand programming concepts to build a Mashup. The basic issues involved in the mashup creation process are data retrieval, source modeling, data cleaning, data integration and data visualization, and user indirectly solves each issue during the Mashup building process by only providing examples [Building mashups by example] as explained next. Figure 1 shows the user-interface of Karma. | |||
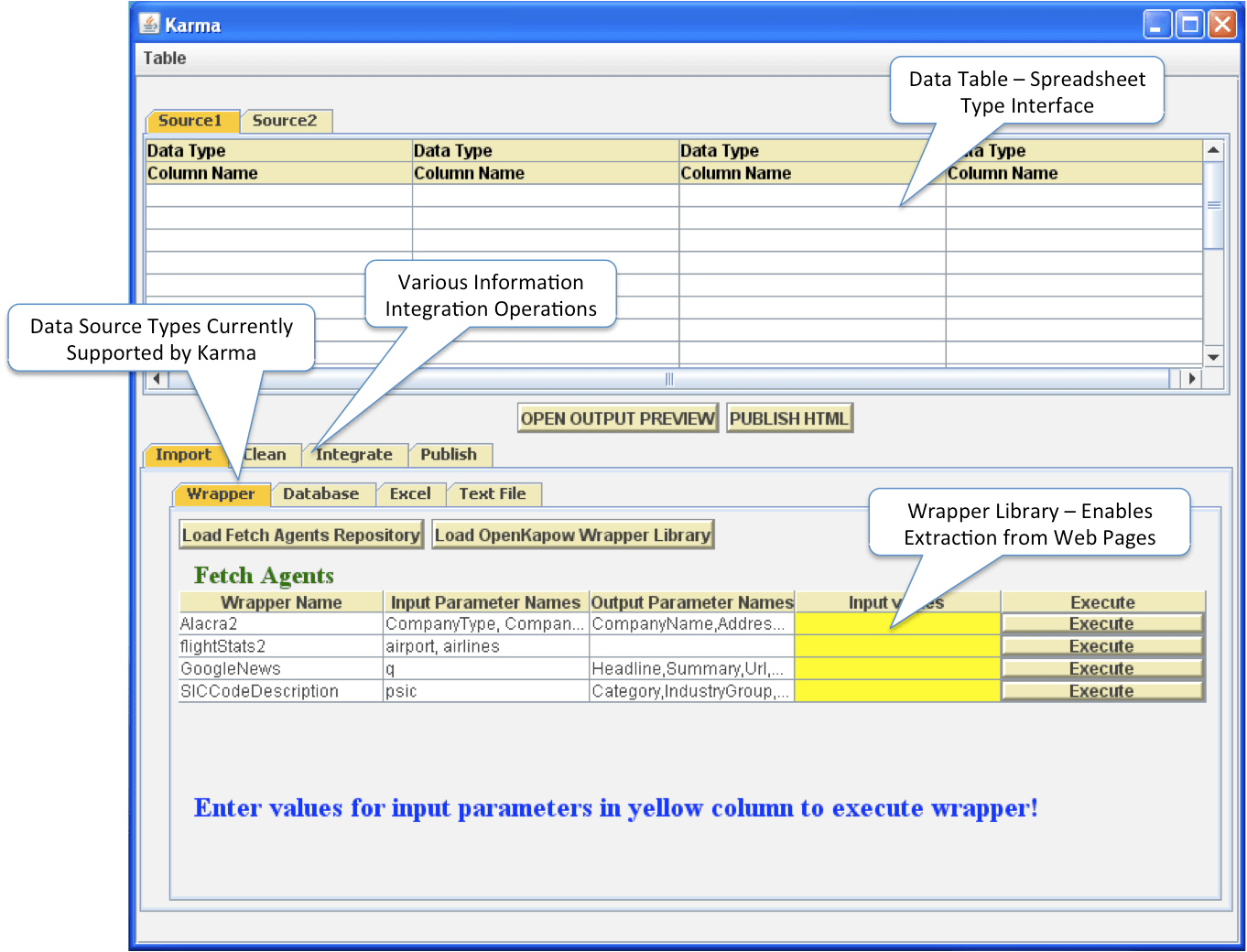 Figure 1. Karma's User Interface |
|||
| Data Retrieval | |||
| Karma enables retrieval of data from semi-structured data-sources like web pages using wrappers, | |||
| and structured data-sources like Excel files, MySQL databases and text files by simply dragging and dropping a sample data element to the Karma’s spreadsheet like interface (Figure 2). The system then learns the path to the similar and parallel data elements and populates them automatically in the data table. Karma maintains a library of wrappers by automatically linking to the OpenKapow and Fetch wrapper repositories present on the local machine. The user can directly execute a wrapper from Karma’s interface by providing values for the input parameters (Figure 1). | 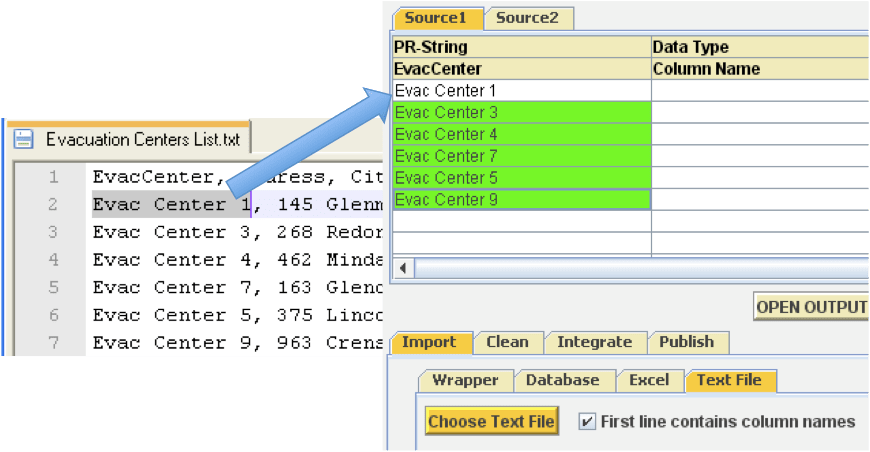 Figure 2. Extracting Data from sample CSV file |
||
| Source Modeling | |||
| Source modeling is the process of learning the underlying model of data source by generating the semantic types of its each attribute. The approach behind learning the semantic types is based on our previous work [Semantic labeling of online information sources] where supervised machine learning techniques are used to generate set of patterns for each semantic type from training data available from sources with known semantics. These patterns are then matched against new input data to identify its semantic type. Semantic types are automatically generated for the data when it is loaded in Karma’s table and or the user can also define a new semantic type by simply typing in into the table as per his understanding. | |||
| Data Cleaning | |||
| Following on the lines of programming by demonstration paradigm, data-cleaning problem is solved by cleaning by example approach that lets users specify how the cleaned data should look like. Karma then induces cleaning transformation rules based on Potter’s Wheel architecture [Raman et al., 2001] from it. For e.g. in order to remove preceding “City of” substring from all rows of “City” column as shown in Figure 3, user needs to provide examples such as “Agoura Hills” for “City of Agoura Hills”. Karma will then try to compute the transformation rules and apply it to other values to fill the “user-defined” column. | |||
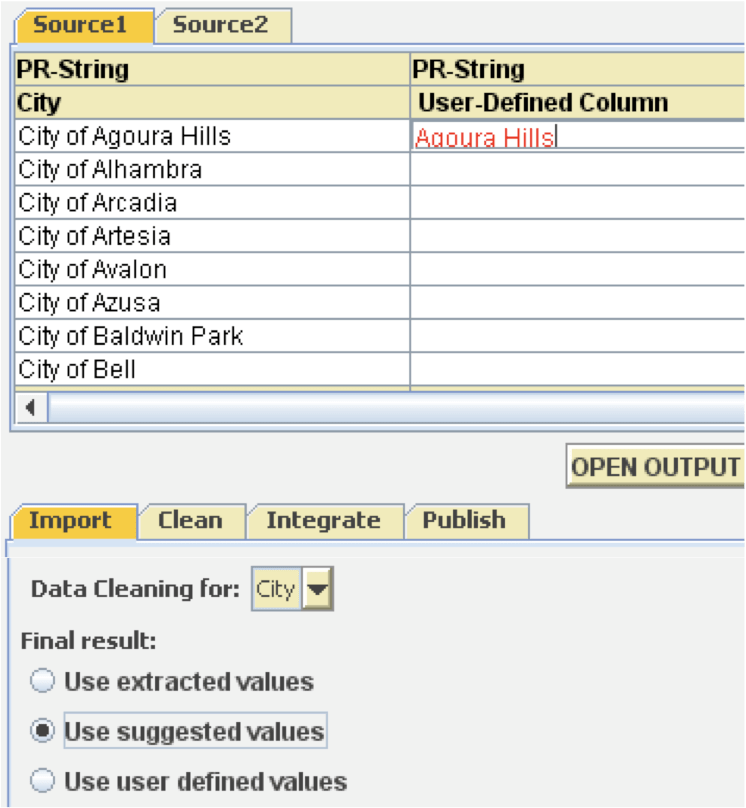 Figure 3. Providing example of cleaned data in Karma during data cleaning |
|||
| Data Integration | |||
| It refers to the process of combining the data from two or more sources, to provide a unified view of data. During Mashup building, the essential problems involved in the data integration include discovering the related sources from the repository or the other current sources being manipulated to combine with the current source, and inferring a query to integrate these sources. | |||
| Karma discovers the related sources for it by automatically detecting and ranking its potential associations with other sources based on the common attribute names, matching semantic types and foreign keys [Interactive Data Integration through Smart Copy & Paste]. It suggests these associations as possible column completions (Figure 4) for new source with a drop down list of names of the new column in the second row. Once the user specifies his choice from the list, Karma defines a “join” query based on the association, executes it, and populates the table with the tuples generated from the query. | 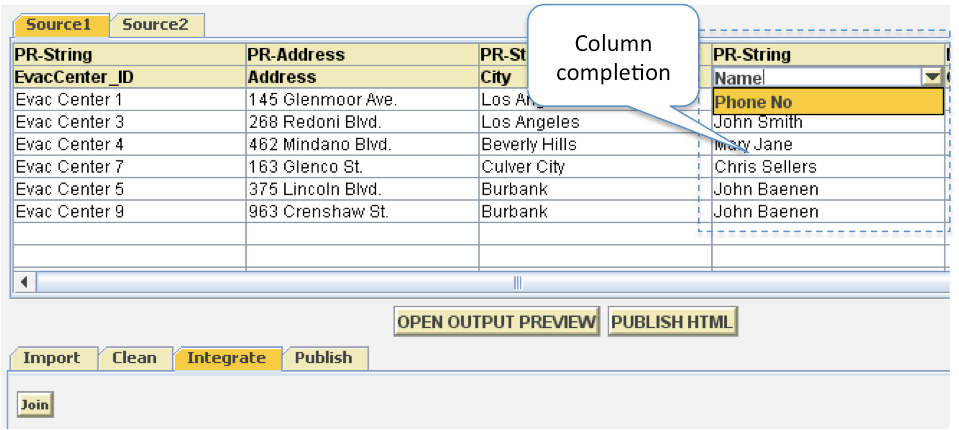 Figure 4. Data Integration in Karma |
||
| Data Visualization | |||
| Based on the programming by demonstration paradigm, Karma enables the user to visualize data in final Mashup output display in different visualization formats such as charts, tables, bulleted lists etc. Karma embodies an output preview window (Figure 5) that provides the platform for customizing Mashup output display and previewing visualized data. The user selects some example data elements from the data for which he wants to specify visualization formatting, and drops it over the interactive pane (in blue color) corresponding to the desired type of visualization. Karma then automatically learns the visualization format with the help of the user-supplied examples, and generalizes it over the remaining data to generate a preview of visualized data in output preview window. It also generates the required program code in background for visualizing the data in specified format in the final mashup output display. Once the user is finished with specifications of data visualization, he can generate the final Mashup by publishing its HTML code. | |||
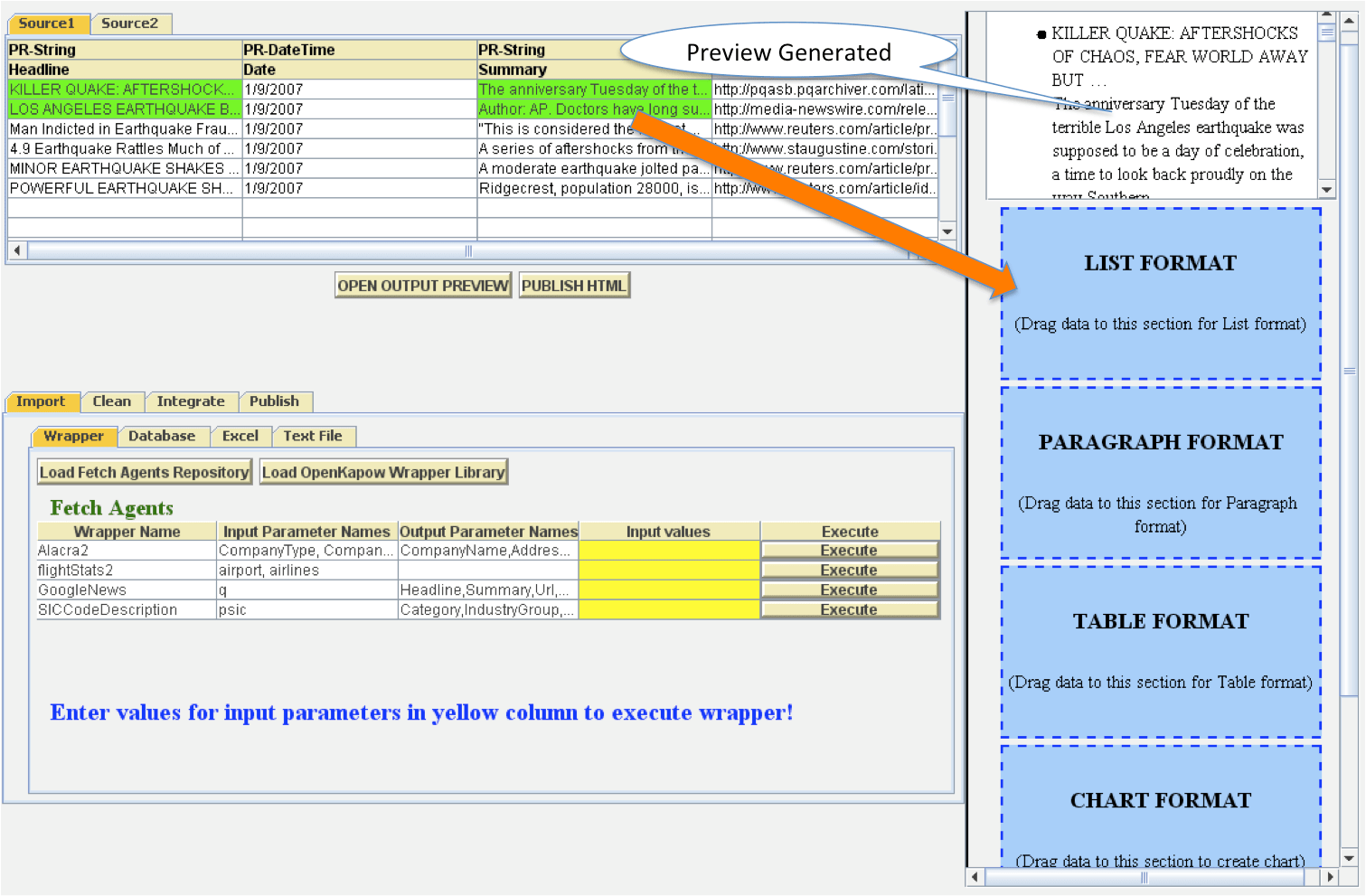 Figure 5. Sample data elements are dragged to the List Format interactive pane for bulleted list visualization. A preview is also generated in the output preview window to assist user |
|||