| Source Modeling | |||
| Only a very small portion of data on the Web is semantically annotated and available for use within Information Integration applications. Semantically annotating existing Web sources requires significant manual effort that must be repeated for each new data source. We have developed an alternative approach that starts with an existing set of known sources and their descriptions, and then goes on to automatically discover new sources and automatically learn their semantic models. | |||
| We developed a system, Deimos, that starts with a set of example sources and their semantic descriptions. These sources could be Web services with well-defined inputs and outputs or even Web forms that take a specific input and generate a result page as the output. The system is then tasked with finding additional sources that are similar, but not necessarily identical, to the known source. For example, the system may already know about several weather services and then be given the task of finding new ones that provide additional coverage for the world and building a semantic description of these new weather services that makes it possible to turn them into Semantic Web Services. | |||
| The overall problem can be broken down into the following subtasks. First, given an example source, find other similar sources. Second, once we have found such a source, extract data from it. For a web service, this is not an issue, but for a Web site with a form-based interface, the source might simply return an HTML page from which the data has to be extracted. Third, given the syntactic structure of a source (i.e., the inputs and outputs), identify the semantics of the inputs and outputs of that source. Fourth, given the inputs and outputs, find the function that maps the inputs to the outputs. Given the semantic description, we can then construct a wrapper that turns the source into a Semantic Web Service that can be directly integrated into the Semantic Web. | |||
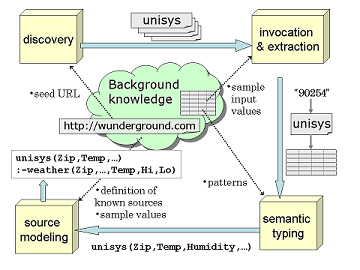 Figure 1: System Architecture |
|||
| We have developed independent solutions to each of these subtasks and integrated them into a single unified approach to discover, extract from and semantically model new online sources. | |||
| Discovery | |||
| Deimos automatically discovers new sources by mining a corpus of tagged Web sources from the social bookmarking site del.icio.us to identify sources similar to a given source. For example, given a weather service that returns current weather conditions at a specified location, the method can identify other weather services by exploiting the tags used to describe such sources on del.icio.us. Tags are keywords from an uncontrolled personal vocabulary that users employ to organize bookmarked Web sources on del.icio.us. We use topic modeling techniques, such as LDA, to identify sources whose tag distribution is similar to that of the given source. | |||
| Invocation and Extraction | |||
| Deimos uses an approach to automatically structure web sources and extract data from them without any previous knowledge of the source. The approach is based on the observation that Web sources that generate pages dynamically in response to a query specify the organization of the page through a page template, which is then filled with results of a database query. The page template is therefore shared by all pages returned by the source. Given two or more sample pages, we can derive the page template and use it to automatically extract data from the pages. | |||
| Semantic Typing | |||
| Deimos uses a domain-independent method to semantically label online data. The method learns the structure of data associated with each semantic type from examples of that type produced by sources with known models. The learned structure is then used to recognize examples of semantic types from previously unknown sources. | |||
| Modeling | |||
| Deimos learns a semantic description of a source that precisely describes the relationship between the inputs and outputs of a source in terms of known sources. This is done as a logical rule in a relational query language Datalog. Mediators can use Datalog source descriptions to access and integrate the data provided by the sources. | |||
| Relevant Publications | |||
|
|||